

Seven practical resources for building effective LLM applications
Seven practical resources for building effective LLM applications
And one not at all practical, but totally awesome one.

Hi and welcome to another resources roundup, and I’m starting this with a quick announcement: I’m thrilled to say that after many years working as a data scientist, I’m going back to my computational linguistics roots, and joining Switzerland’s largest telecommunications provider to help them build out their conversational AI systems. So if my content starts to skew a little more towards LLMs- and NLP, you’ll know why. But there’ll still be plenty here for anyone who signed up for topics like data science, engineering, AI ethics and innovation. I haven’t lost interest in these areas, which means I still have loads more interesting and useful resources to share.
So with that exciting news broken, let’s kick off another resources roundup, this time dedicated to getting LLM-powered systems into production. I’ve roughly organised these from beginner to advanced, based on the flight level or degree of complexity of the information. So feel free to jump in wherever it suits you. Enjoy!

What Does the ML Lifecycle Look Like for LLMs in Practice?
For: data scientists, engineers and managers at the very beginning of their LLM development journey.
Let’s start with the basics: What does the LLM-system development lifecycle look like, and how does it differ from traditional ML development? As author Haley Massa (field Data Scientist at Arthur AI) points out, “although LLMs are trying to carve out their own phrase within MLOps (LLMOps) […] they’re still machine learning systems. This means that even if they use different tools or phrases, they still follow most of the same lifecycle and best practices.” This nicely illustrated article does a great job at explaining the similarities and differences between building ML- versus LLM-based software solutions.
. Finally, the production pipeline typical of ML systems is replaced by an “application schema,” which defines how the application is implemented and interacted with via prompt orchestration with various tools.")
Patterns for Building LLM-based Systems & Products.
For: Courageous beginners, and those already in the trenches.
This is one of those pieces which will exponentially increase the length of your to-read list, thanks to all the useful links it includes. But even if you manage to resist those, there’s still a tonne to take in here, as author Eugene Yan (Senior Applied Data Scientist, Amazon) provides super-detailed explanations of the what, why, and how for seven patterns for building Large Language Model-based products. The patterns cover everything from architecture to evaluation to safeguarding models. Specifically, they include:
Evals: To measure performance
RAG: To add recent, external knowledge
Fine-tuning: To get better at specific tasks
Caching: To reduce latency & cost
Guardrails: To ensure output quality
Defensive UX: To anticipate & manage errors gracefully
Collect user feedback: To build our data flywheel
Plus, there’s a helpful addendum on how to match these LLM patterns to potential problems.
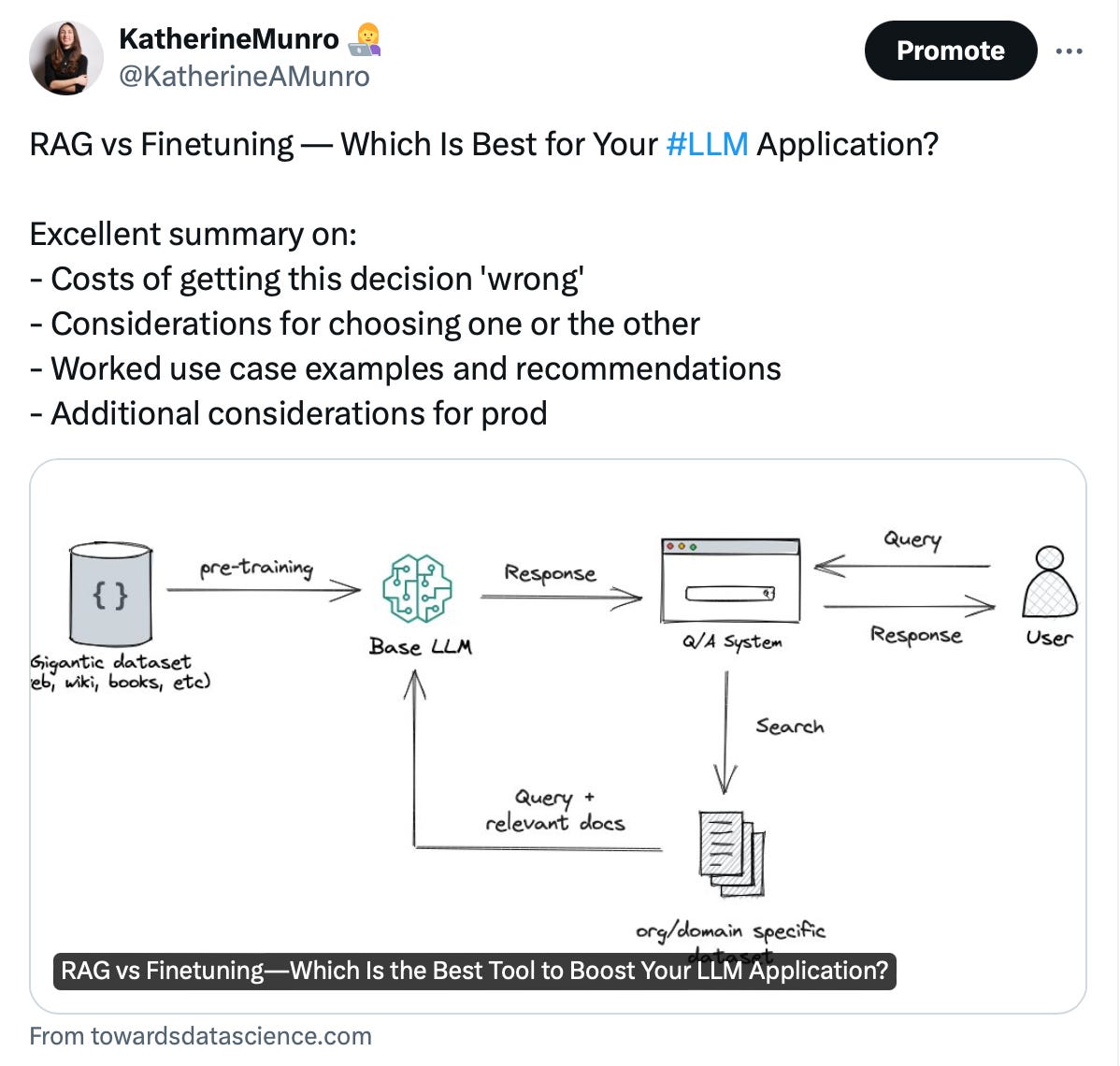
RAG vs Finetuning — Which Is Best for Your LLM Application?
For: Anyone involved in making the call on one architecture or another.
Speaking of LLM design patterns, let’s zoom in on one common question: Do you need to fine-tune an LLM on your organization’s data, or could you augment an LLM with your documents, which it can then retrieve and use to generate outputs (aka. a Retrieval Augmented Generation application)? Heiko Hotz, “Generative AI Global Blackbelt” at Google, provides a definitive guide to help you decide. This includes considerations for choosing one or the other, use case examples and recommendations, costs of getting this decision 'wrong', and additional considerations for going to production. And while he only covers these two design patterns, the way he thinks about it can be useful for assessing other options too, like RAG vs fine-tuned vs agent-based LLM systems.1
Article: 7 Must-Have Features for Crafting Custom LLMs.
For: Those brave enough to consider fine-tuning a custom LLM.
Or, if you’re thinking of creating your own model, Ben Lorica (Chair of The AI Conference and Host of the Data Exchange podcast), presents seven foundational requirements for doing so, and shows how these requirements reflect the unique promise and challenges of custom LLMs. He points out that the current landscape of tools for pre-training, customizing, optimizing, and deploying LLMs is pretty wild, but by sticking to these seven principles, developers will be able to confidently select and adapt their tech stack as the field matures and new data or better strategies emerge.
Challenges and Applications of Large Language Models.
For: Pessimists with a lot of time on their hands.
Ok, I’m joking about the pessimistic part. I find that in product development, solving challenges is half the fun. So let’s instead say curious: If you’re curious, and patient, then feel free to lose yourself in this 72-page research paper on the trickiest parts of productionizing LLM systems. This includes the hurdles you’ve no doubt heard before, like high inference latency, but plenty of other issues you probably never worried about (congrats, now you can). It’s also the inspiration for the “Harry Potter and the Unfathomable Dataset” graphic that started this post.
Open LLM Kickstarter (GitHub Repo).
For: Those with itchy fingers.
If you’re undeterred by the last resource, that’s great! Let’s say you now want to explore open source LLMs but you don't have the memory to load big models, or the compute power to run inference quickly, or you just don't know where to start. What can you do? You can check out this quickstart repo, which contains infra to provision a GPU instance on GCP, a kickstarter notebook for loading and running open source LLMs, and a Streamlit app to let you chat with your LLM.
Why you still need NLP skills in “the age of ChatGPT.”
For: Anyone wondering whether and how NLP is still applied in an LLM-crazed world.
This one is a little self-promotional, but I’m including it because it’s very relevant to today’s topic. It’s my last post, detailing four reasons NLP skills are still useful in building LLM-powered applications. Look out for a follow up post, where I’ll show practical examples based on my own work experience.

Something just for fun.
For: Anyone who thinks you need to be sentient to write a poem like "Green Eggs and Ham."
This last resource won’t help you take an LLM-application to production (unless you need to win stakeholder buy-in with a whimsical demonstration of how the tech works, that is!). It’s a tiny language model made from matchboxes, and I’m just including it because it’s great.
I didn’t talk much about agent systems in this article, but in my last post I linked to Expanding AI Horizons: The Rise of Function Calling in LLMs, which provides a nice introduction to Transforming Text Models into Dynamic Agents.